Introducción
El propósito de este documento es por una parte, describir los aspectos más importantes de los procesos ETL por sus siglas en Inglés: Extracción, Transformación y Carga- , que se requieren para lograr una buena calidad de los datos antes de cargarlos al repositorio de información básica y por otra, lograr un mejor entendimiento de la complejidad e importancia de los mismos.
Los diagramas del flujo de datos que se presentan, muestran un esquema de la definición del modelo que debe adoptarse para almacenar los datos de una operación estadística en el repositorio de información básica, antes de difundirlos dinámicamente por Internet. Cuando al definir las especificaciones del diseño detallado de los procesos, archivo por archivo y campo a campo, el diseñador encuentra alguna diferencia con el marco general descrito, ésta debe ser explicada y documentada.
Los procesos de Extracción, Transformación y Cargue a que nos referiremos, se han clasificado en siete subprocesos a saber:
1. Procesos de Extracción
2. Procesos de Transferencia
3. Procesos de Filtración y Estandarización
4. Procesos de Validación y Limpieza
5. Procesos de Transformación y Consolidación
6. Procesos de Carga
7. Procesos de Control de Calidad
Como estrategia de diseño, se incluye además la descripción de las reglas de transformación o preparación que deben aplicarse en cada subproceso. No se están considerando las reglas en los subprocesos numerados 1, 2, 6 y 7, porque en ellos no hay transformación alguna de sus datos.
El objetivo más importante de este diseño es el descubrimiento, la documentación y la programación de las reglas de calidad que deben aplicarse a los datos antes de ser cargados al repositorio de información básica. Dichas reglas, llamadas en general reglas de transformación o preparación, deberán descubrirse y documentarse en la siguiente secuencia:
- Filtración y Estandarización
- Reglas de Filtración
- Reglas de Estandarización
- Reglas de Integración
- Validación y Limpieza
- Reglas de Validación
- Reglas de Limpieza
- Transformación y Consolidación
- Reglas de Transformación
- Reglas de Consolidación
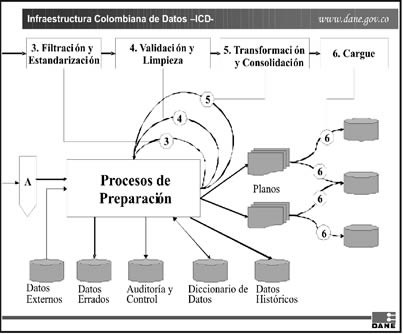
En la Figura No. 1 se presenta un esquema resumido de los procesos de transformación o preparación de los datos, antes de cargarlos al repositorio de información básica. Estos procesos de transformación cobran especial importancia porque es allí donde realmente se da inicio al diseño y programación de las reglas de calidad de datos que deben aplicarse antes de almacenarlos en el repositorio de información básica.
Figura No. 1.- Procesos de Preparación
En este artículo, se desarrollarán los tres primeros subprocesos y sus correspondientes reglas de calidad, cuando sea del caso. Por lo tanto, los subprocesos numerados 4, 5, 6 y 7, se tratarán en próximas entregas de la “Revista de la Información Básica IB-“.
1. Procesos de Extracción
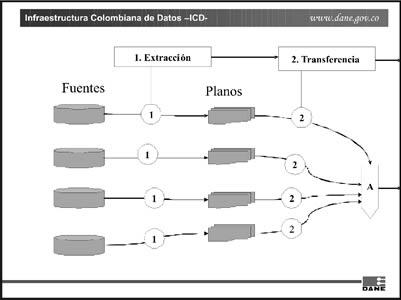
- Entradas: (Ver figura No. 2)
- Fuentes de datos para cada operación estadística.
- Salidas:
- Archivos planos de datos
- Reportes de Log's del proceso1
- Registros de Auditoría y Control
- Diccionario de datos
Figura No. 2.- Procesos de Extracción y Transferencia
Descripción del proceso:
En Este documento se hace referencia al conjunto de archivos fuentes, resultantes de los procesos de recolección y depuración propios de una operación estadística, y que han sido definidos, descritos, evaluados y documentados previamente durante la fase de planeación metodológica de la operación.
Las salidas reposan en la misma plataforma de entrada, a menos que la extracción y la transferencia se requieran hacer en un solo paso. Los archivos planos de salida son generalmente una copia completa de las fuentes, pero podrían estar filtrados (ver proceso de filtración). El método de extracción depende de la plataforma de origen, así:
Plataforma RDBMS.2- Se leen las estructuras de las tablas de la base de datos; también se construyen las estructuras de los planos de salida. Ambas son almacenadas en el diccionario de datos. Se genera el programa y el código necesario que baja los archivos planos de las tablas de la base de datos. Dichos programas son almacenados en una estructura de directorios como por ej.: programas/rdbms/basedatos/nombre.pgm del servidor y de la estación de trabajo, para su posterior compilación y ejecución.
Otras plataformas: Access, FoxPro, DBase, Excel, Archivos Planos.- Se generan la estructuras y se almacenan en el diccionario de datos. Usando las facilidades de dichas herramientas, se construyen los archivos planos de entrada y de salida, en formato csv, por ejemplo.
El reporte de auditoría y control de la extracción debe contener al menos la siguiente información:
- Fecha y hora de la extracción
- Período de los datos extraídos, con fecha y hora desde, y con fecha y hora hasta.
- Totales de control, cualitativos y cuantitativos para los campos seleccionados.
- Conciliación de los totales de control
2. Procesos de Transferencia
- Entradas:
- Archivos planos de datos en la plataforma de origen:
- IBM, Unisys, Unix, Windows, etc.
- Salidas:
- Archivos planos de datos en la plataforma de destino:
- IBM, Unisys, Unix, Windows, etc.
- Reportes de Log's del proceso
Descripción del proceso:
Las fuentes pueden ser leídas en tandas o en línea, dependiendo del volumen de datos y de la velocidad de transmisión en la red utilizada.
Los archivos planos son transferidos a la plataforma de destino utilizando la técnica de ftp (file transfer protocol), o utilizando las facilidades por tandas o en línea que brinda la herramienta ETL. Se debe observar que, para algunas plataformas, se requiere conversión de código de caracteres EBCDIC a ASCII o viceversa.
3. Procesos de Filtración y Estandarización
3.1. Filtración - Entradas: (Ver Figura No. 3)
- Fuentes (planos) de datos autorizadas para cada grupo de información
- Fuentes (planos) de datos comunes y/o redundantes
- Diccionario de datos
- Salidas:
- Archivos de datos a estandarizar
- Archivos de datos filtrados que no requieren estandarización
- Reportes de Log's del proceso
- Registros de Auditoría y Control
- Diccionario de datos
Figura No. 3.- Procesos de Filtración y Estandarización
3.1.1 Descripción del proceso:
En términos generales, la filtración se lleva a cabo eliminando aquellos datos que no necesitan ser incluídos en las tablas de destino. Los archivos, los campos de los archivos que no tienen cruce con los datos de destino, o los registros que cumplan ciertas condiciones, son excluídos. Los que deben ser incluídos se separan entre aquellos que requieren estandarización y los que no la requieren.
Las fuentes de datos comunes o redundantes son las requeridas para conservar la integridad referencial de los registros eliminados durante la filtración.
El reporte de auditoría y control de la filtración debe contener al menos la siguiente información:
- Conteo de registros filtrados por el usuario
- Conteo de registros filtrados por el sistema
- Para los registros filtrados y los no filtrados, o Totales de control, cualitativos y cuantitativos para los campos seleccionados.
- Conciliación de los totales de control
3.1.2 Reglas de Filtración:
La filtración puede ser aplicada a uno o más de los siguientes niveles:
- Remoción de los campos campos individuales de un archivo. En este caso, la regla es la indicación del campo que debe ser excluido. La regla se aplica al campo.
- Remoción de una o más filas o registros completos de un archivo. Estas reglas especifican las condiciones bajo las cuales el registro debe ser excluido. Las reglas se aplican al archivo.
Por ej.: Si la fecha de vigencia es menor que yyyymmdd, excluir el registro.
Este tipo de filtración debe usarse con precaución porque puede resultar un destino final con información inválida o incompleta, dadas las consideraciones del siguiente punto: integridad referencial
- Remoción de un conjunto de datos lógicamente relacionados para mantener la integridad referencial. Para este caso, además de la condición del punto anterior, la regla especifica los campos o registros del(os) otro(s) archivo(s), que deben excluirse para mantener la integridad referencial entre las entidades lógicamente relacionadas.
3.2. Estandarización
- Entradas: (Ver Figura No. 3)
- Archivos de datos a estandarizar
- Archivos de estándares
- Archivos externos (de otras empresas) para comparación
- Salidas:
- Archivos de datos estandarizados
- Reportes de Log's del proceso
- Registros de Auditoría y Control
- Diccionario de datos
3.2.1 Descripción del proceso:
El objetivo del proceso es estandarizar los datos en valores atómicos3, sus formatos y sus valores, de manera que un formato consistente sirva después para identificar registros duplicados, validarlos y consolidar fuentes comunes o redundantes. El proceso aplica las reglas de estandarización a los datos.
El reporte de auditoría y control de la estandarización debe contener al menos la siguiente información:
- Conteo de registros estandarizados
- Conteo de registros no estandarizados
- Para los registros estandarizados y los no estandarizados o Totales de control, cualitativos y cuantitativos para los campos seleccionados.
- Conciliación de los totales de control
- Conteo del perfil de los campos estandarizados en el registro
3.2.2 Reglas de Estandarización:
Estas reglas convierten los formatos de campos no estandarizados a valores estándares. Los campos no estandarizados son aquellos en los cuales dos valores diferentes significan lo mismo o están en formato inconsistente, creando problemas para su utilización.
Los ejemplos más importantes, son:
3.2.2.1 Redundancia de valor en el dominio.- Diferentes valores del campo tienen el mismo significado, lo cual no permite analizar los datos consistentemente para dicho campo. La redundancia se da en un atributo de un archivo/tabla.
Acción de estandarización.- Acordar con los líderes de las áreas funcionales y representantes de los usuarios un estándar para el valor del campo y definir la regla de transformación que convierte los datos no estandarizados a un valor estándar.
Ejemplo.- Un “producto” tiene un atributo que se llama “unidad de medida” y existen diferentes productos que pueden ser vendidos por docena; pero la docena es representada en unos casos por 12, o doc., o dc, o docena. Por lo tanto, se debe definir un estándar para la(s) unidad(es) de medida y su correspondiente regla de transformación.
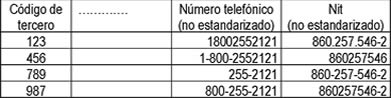
3.2.2.2 Inconsistencias de Formato.- Los valores de un campo están almacenados inconsistentemente en diferentes formatos, lo cual impide encontrar ocurrencias duplicadas en el archivo. Acción de estandarización.- Acordar con los líderes de las áreas funcionales y representantes de los usuarios un estándar para el formato del campo y definir la regla de transformación que convierte los datos no estandarizados a un formato estándar.
Ejemplo.- El número telefónico, el NIT, etc., son campos comúnmente no formateados o formateados inconsistentemente. Por lo tanto, se debe definir un estándar para el formato del campo y su correspondiente regla de transformación. En ciertos casos, como el número telefónico, es necesario abrir el campo para desagregar código de área, ciudad, teléfono.
3.2.2.3. Valores no atómicos en los datos.- El principio de valores atómicos significa que los atributos o campos deben estar definidos de tal manera que contengan el más bajo nivel que se requiere conocer. Para propósitos de validación y limpieza, permite encontrar más fácilmente los duplicados y hace más eficaz la consolidación de archivos. Así mismo, las reglas de transformación se pueden aplicar más eficientemente. A esta técnica también se le conoce con el nombre de “Filtro Horizontal”.
Acción de estandarización.- Romper los componentes individuales de un campo en atributos separados para analizar su significado o eliminar duplicados.
Ejemplo.- Los campos de nombres y direcciones son ejemplos clásicos de este tipo de estandarización, pero no los únicos. Un campo de nombre puede contener hasta cinco o seis campos separados en atributos atómicos.
Al estandarizar, se facilita encontrar los duplicados, v.g
3.2.2.4. Valores con significado embebido.- Un problema común en los datos es el significado embebido para ahorrar espacio o crear identificadores con grupos contenidos en la llave primaria. Con ello se dificulta el desglose de las jerarquías y, por tanto, la granularidad de la entidad queda escondida.
Acción de estandarización.- Romper las componentes embebidas en varios atributos separados para obtener los diferentes niveles de la jerarquía y facilitar el manejo de cambios. Esto equivale a normalizar la entidad.
Ejemplo.- En una industria editora el código de producto está compuesto de seis dígitos: los dígitos 1 y 2 identifican la línea de producto; los dígitos 3 y 4 identifican el producto y los dígitos 5 y 6 identifican el subproducto.
3.2.2.5. Actividades que se realizan para el proceso de estandarización.-
1. Identificar los datos que necesitan estandarización y las fuentes comunes de datos entre los archivos fuentes.
2. Establecer, de común acuerdo con los líderes de las áreas funcionales y representantes de los usuarios, el conjunto de valores estándares que se deben adoptar para cada campo y las reglas de estandarización correspondientes.
3. Documentar los estándares, indicando el líder o usuario responsable de su definición.
4. Documentar las reglas de calidad que deben aplicarse para la transformación de los datos.
3.3. Integración
- Entradas: (Ver Figura No. 3)
- Archivos de datos filtrados que no requieren estandarización
- Archivos de datos estandarizados
- Diccionario de datos
- Salidas:
- Archivos integrados de datos estandarizados
- Archivo de registros duplicados
- Tabla de referencia de identificadores
- Reportes de Log's del proceso
- Registros de Auditoría y Control
- Diccionario de datos
3.3.1. Descripción del proceso:
Durante el proceso se integran los archivos de datos que no requieren estandarización con los de datos que fueron estandarizados. Usando técnicas de Match&Merge4; se descubren los registros duplicados y se integran. El resultado final son unos archivos integrados y estandarizados, listos para ser validados.
El proceso de integración examina datos estandarizados para encontrar duplicados de una entidad, tal como hogar o persona, ya sea dentro de una base de datos o archivo, o entre archivos diferentes; al integrar los duplicados, también es necesario volver a relacionar los datos asociados con otras tablas; por supuesto, para conservar la integridad de los datos se debe crear y mantener una tabla de referencias cruzadas para los identificadores de la entidad.
Para este paso, son muy útiles las herramientas de validación y limpieza, sobre todo aquellas que utilizan técnicas de descubrimiento de reglas, basadas en semejanza de ocurrencias.
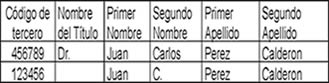
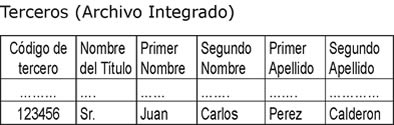
Ejemplo de una tabla de referencia cruzada de identificadores:
Todos los archivos de una entidad, con los datos estandarizados, pueden ahora cruzarse consigo mismo o con otros para descubrir o encontrar duplicados e integrarlos. El proceso aplica las reglas de integración.
El reporte de auditoría y control de la integración debe contener al menos la siguiente información:
- Conteos de registros duplicados y consolidados
- Conteos de ocurrencias de cada registro duplicado
- Para los registros duplicados y los no duplicados:
- Totales de control, cualitativos y cuantitativos para los campos seleccionados.
- Conciliación de los totales de control
3.3.2. Reglas de Integración:
Las reglas de integración son de dos clases: aquellas que definen los criterios de igualdad para descubrir posibles duplicados y aquellas que integran los duplicados y relacionan los datos integrados con las ocurrencias defectuosas.
Las tareas para la identificación de las reglas comprenden:
- Seleccionar los atributos que puedan tener posibles ocurrencias de duplicados y establecer criterios de igualdad (match) o semejanza.
- Determinar el peso relativo de cualquiera, o cada uno de los atributos utilizados, para definir el criterio de igualdad. Por ej., el nombre de una persona pesa más que el nombre de la calle en su dirección; dos cédulas de ciudadanía iguales con semejanza en el nombre de la persona, pesan más que dos nombres de persona iguales con semejanza en la cédula de ciudadanía.
- Determinar las técnicas que se deben utilizar para encontrar campos duplicados:
- Igualdad exacta de caracteres en los valores de los campos
- Igualdad de algunos caracteres claves
- Frases iguales contenidas en el texto
- Palabras claves iguales
- Palabras claves inteligentes o alias de un nombre
- Igualdad o semejanza fonética
- Parecido por transposición de caracteres
- Comparar los criterios de semejanza de un registro específico con los demás del mismo archivo.
- Comparar los criterios de semejanza de un registro específico con los demás de otros archivos.
- Evaluar las ocurrencias semejantes para asegurarse de que en realidad son duplicados.
- Crear las tablas de referencias cruzadas de identificadores como mecanismo de control.
- Documentar los criterios de igualdad o semejanza.
- Integrar los duplicados en una sola ocurrencia.
- Transformar el archivo y los demás relacionados con éste, reemplazando los múltiples identificadores por el identificador único. Esta operación debe necesariamente validarse.
- Mantener los archivos originales por un período de tiempo prudencial en caso de presentarse alguna contingencia.
Observar que las primeras de estas tareas definen los criterios de igualdad o semejanza, mientras que las tres últimas integran los duplicados.
3.3.2.1. Igualdad o semejanza de campos.- Estas reglas definen los criterios de igualdad (match) que deben aplicarse a los datos para determinar sus duplicados.
Es importante y necesario que antes de aplicar estas reglas se validen los componentes del identificador, especialmente cuando es formado por varios campos. Para este paso, también son muy útiles las herramientas de validación y limpieza.
3.3.2.2. Integración de duplicados.- Esta transformación es usada para integrar o eliminar duplicados en registros múltiples de datos, dentro de un archivo o entre archivos diferentes, cuando hay ocurrencias comunes. La tabla de referencias cruzadas de los identificadores, creada en el paso anterior del proceso de integración, se usa para conservar la integridad referencial entre las entidades relacionadas, transformando los identificadores a sus valores únicos. Por ej., cuando varios registros de terceros (456789, A12, B93, 123456) son integrados en uno solo (123456), el valor del identificador 123456 debe reemplazar los valores de los identificadores presentes en la tabla de referencias cruzadas. Los datos de las fuentes más autorizadas, conforman el registro completo.

1 Los reportes de Log´s y el contenido del diccionario de datos en todos los procesos se considerarán dentro de los subprocesos de control de calidad. 2 RDBMS: Relational Data Base Management System.
3 Un valor atómico se refiere a la unidad más pequeña de descomposición de un campo.
4 Las técnicas Match&Merge cruzan dos o más archivos basados en un identificador común.
Bibliografía
English, Larry P., Improving Data Warehouse and Business Information Quality. New York: John Wiley and Sons, 1999.
English, Larry P., Information Quality Assessment, Data Cleansing and Transformation Processes. The Data Warehousing Institute: The fifth annual Implementation Conference, 2000.
Wells, David, Techniques for Extracting, Transforming and Loading Data. The Data Warehousing Institute: The World Conference Spring, 2001.
Brackett, Michael H., Data Resource Quality: Turning Bad Habits into Good Practices. Englewood Cliffs, NJ: Addison Wesley Longman, 2000.
Olson, Jack E., Data Quality: The accuracy Dimension. San Francisco, Morgan Kaufmann, 2003.
Loshin, David, Enterprise Knowledge Management: The Data Quality Approach. San Francisco, Morgan Kaufmann, 2001.
Duncan, Karolyn and Wells, David, Rule Based Data Cleansing. The Journal of Data Warehousing, Fall, 1999.
Villan Criado, Ildefonso y Bravo Cabria, María Soledad, Procedimientos de Depuración de Datos Estadísticos, EUSTAT, Cuaderno 20, Seminario Internacional de Estadística en Euskadi, 1990.
|