Resumen
El sector público no es inmune a los problemas de calidad de datos. En muchos casos se enfrenta a situaciones que son más difíciles de solucionar que las que se dan en el sector privado. No necesariamente es peor que en el sector privado, pero ciertamente, no es mejor en la mayoría de los casos. A pesar de su poder para legislar, regular y obligar, en el gobierno están presentes los problemas que cubren toda la gama de atributos de calidad en los datos: exactitud, integridad, consistencia, oportunidad, unicidad y validez, sin dejar de mencionar la falta de credibilidad derivada de fenómenos políticos y administrativos.
El presente artículo está dirigido a aquellas personas que no creen en las bondades de realizar un buen diseño de procesos antes de iniciar su programación, pero también a las que, creyendo en dichos beneficios, no los realizan por una u otra razón, entre ellas, porque simplemente consideran que no poseen o no les dejan tener tiempo y se atienen a las consecuencias en detrimento de la calidad de los resultados de su trabajo.
Este artículo continúa con la discusión sobre el uso de una tecnología denominada “perfil de datos”, cuyo propósito es descubrir el verdadero contenido, estructura y calidad de los datos, como una estrategia primordial del plan de aseguramiento y control de calidad.
En esta segunda parte, continuamos con los procesos de validación, limpieza, transformación, consolidación y cargue al repositorio, de los datos que provienen de distintas fuentes y se describen y precisan las reglas de calidad aplicables a ellos según el caso.
Deseo expresar mis agradecimientos por la colaboración y sugerencias del grupo de trabajo del DANE, conformado por Carla P. Durango V., Cristian J. Sánchez y José A. Pedraza, quienes han colaborado en el diseño y la construcción del Repositorio de Información Básica y, de una u otra forma, ayudaron a completar este ejercicio.
Palabras claves
Calidad de datos, Repositorio de Información Básica, Infraestructura Colombiana de Datos, Reglas de Calidad de datos, Procesos de Extracción, Transformación y Cargue ETC-
Abstract
The public sector is not immune from data quality problems. In many cases, it faces even more difficult situations than the ones the private sector does. It is not necessarily worse than in the private sector, but it is certainly not better in many cases. In spite of its power to legislate, regulate and enforce, the government faces problems that cover the gamut of data quality attributes: accuracy, completeness, consistency, timeliness, uniqueness and validity, with no exception being the lack of credibility due to political and administrative phenomenons.
The present article is directed to those people who don't believe in the benefits of making a good design of processes before initiating their programming effort, but also, to those who believing in such benefits, don't make it for some reason, like for example, not having enough time or having a short deadline imposed to them, assuming the consequences of damaging the quality of the result of their work.
This article continues with the discussion about the use of data profiling technology to discover the true content, structure, and quality of data, as well as the central strategy for a data quality assurance and control program.
In this second part, we continue with the validation, cleansing, transformation, consolidation and loading processes needed to prepare the different data sources, before loading the repository, and describing the data quality rules applicable to them in each case.
I finally wish to express my thanks for the kind suggestions of the working group at DANE including Carla P. Durango V., Cristian J. Sánchez and José A. Pedraza, who have helped in the design and construction of the Basic Information Repository, and brought this exercise to completion through their professional interaction with me.
Key words
Data Quality, Basic Information Repository, Colombian Data Infrastructure, Data Quality Rules, Extraction Transformation and Load ETL- Processes.
Introducción
Este documento, en su segunda parte, tiene el mismo propósito del anterior1, es decir, por un lado, describir los aspectos más importantes de los procesos ETL por sus siglas en Inglés: Extracción, Transformación y Carga- , que se requieren para lograr una buena calidad de los datos antes de cargarlos al repositorio de información básica del DANE y, por otro, lograr un mejor entendimiento de la complejidad e importancia de los mismos, cuando tratamos con grandes volúmenes de datos.
Los diagramas del flujo de datos que se presentan muestran un esquema de diseño del modelo que debe adoptarse, antes de almacenar los datos de una operación estadística en el repositorio de información básica. Este modelo servirá de base para definir las especificaciones del diseño detallado de los procesos, archivo por archivo y campo a campo, para una operación estadística.
Continuando con el artículo anterior2, los procesos de Extracción, Transformación y Cargue a los que nos referiremos ahora, serán:
1. Procesos de Validación y Limpieza
2. Procesos de Transformación y Consolidación
3. Procesos de Carga
4. Procesos de Control de Calidad
Como estrategia de diseño, se incluye además la descripción de las reglas de transformación o preparación que deben aplicarse en cada subproceso. Dichas reglas deberán descubrirse y documentarse en la siguiente secuencia, para facilitar la labor de programación.
Validación y Limpieza
- Reglas de Validación
- Reglas de Limpieza
Transformación y Consolidación
- Reglas de Transformación
- Reglas de Consolidación
Con el fin de recordar el diseño global, en el gráfico 1 se presenta un esquema resumido de los procesos de preparación de los datos. Estos procesos cobran especial importancia porque es allí donde realmente se da inicio al diseño detallado y la programación de las reglas de calidad de datos que deben aplicarse a la operación estadística, antes de almacenarla en el repositorio de información básica.
Gráfico 1. Procesos de Preparación
1. Procesos de Validación y Limpieza
1.1. Validación
Entradas: (Ver Gráfico 2)
- Archivos integrados de datos estandarizados, los cuales comprenden: Tablas de Referencia; archivos de Datos Maestros; archivos de Datos Primarios Recolectados y archivos Externos Estandarizados.
- Diccionario de datos.
Salidas:
- Archivos de datos estandarizados y validado
- Archivos de datos defectuosos e incompletos
- Reportes de Log's del proceso
- Registros de Auditoria y Control
- Diccionario de datos
Gráfico 2. Procesos de Validación y limpieza
1.1.1. Descripción del proceso
La validación de datos es un proceso iterativo de tantos ciclos como sean necesarios para alcanzar el nivel de calidad deseado. Se aplican las reglas de validación a los datos y se separan aquellos que las cumplen de los que las violan. Estos últimos pasarán por un proceso de limpieza.
Reporte de auditoria y control de la validación: debe contener, al menos, la siguiente información:
- Conteo de registros válidos e inválidos
- Conteo de campos válidos e inválidos
- Conteo de registros y campos sospechosos
- Para los registros válidos e inválidos,
- Totales de control, cualitativos y cuantitativos para los campos seleccionados.
- Conciliación de los totales de control
1.1.2. Reglas de Validación
En el número 3 de ib Revista de la Información Básica, se encuentra un artículo, también de este autor, donde se plantea una forma de descubrir y documentar las reglas de validación. Por ello, y por razones de espacio, obviamos tratar el tema en el presente artículo.
1.2. Limpieza
Entradas:
- Archivos de datos defectuosos o incompletos
- Archivos de datos comunes y redundantes
- Diccionario de datos
Salidas:
- Archivos de datos limpios y completos
- Archivos de datos para revisión físico manual
- Reportes de Log's del proceso
- Registros de Auditoria y Control
- Diccionario de datos
1.2.1. Descripción del proceso
Este proceso, como el anterior, es iterativo, con tantos ciclos como sean necesarios para alcanzar el nivel de calidad deseado. Los datos se corrigen y completan electrónicamente. Se aplican las reglas de imputación y limpieza. Aquellos que no puedan corregirse o completarse electrónicamente, pasarán por un proceso de revisión y/o recolección físico-manual.
Reporte de auditoría y control de la limpieza: debe contener, al menos, la siguiente información:
- Conteo de registros corregidos, imputados e intactos
- Conteo de campos corregidos, imputados e intactos
- Conteo de registros y campos sospechosos
- Para los registros corregidos, imputados e intactos,
- Totales de control, cualitativos y cuantitativos para los campos seleccionados.
- Conciliación de los totales de control
1.2.2. Reglas de Limpieza
Una vez que las reglas de validación han sido identificadas y documentadas, necesitamos determinar las reglas de limpieza. Recordemos que las reglas de validación se refieren a la forma como los datos cumplen con las reglas de integridad del negocio, mientras que las reglas de limpieza especifican las acciones a tomar cuando se detectan violaciones a las reglas de validación.
A continuación, se presentan el marco conceptual y una serie de recomendaciones para determinar las reglas de limpieza. Dichas reglas, conocidas en el medio estadístico como de “imputación”, son materia de tratados específicos y, por ello, no se describen en este documento.
La auditoría de los datos, que también hemos llamado el análisis y la evaluación de la calidad de los datos, es un paso esencial para conocer las reglas de validación y por ende las de limpieza. Es imposible conocer el alcance del problema, o determinar la necesidad de una solución, hasta tanto el problema no sea bien entendido. Por ello, el proceso de auditoría implica observar realmente los datos para entender su contenido, estructura, distribución de valores y otras circunstancias, que indiquen si los datos son inválidos o por lo menos sospechosos, para conocer el tamaño y alcance de la situación, pero sin arreglar ningún problema, todavía. Este entendimiento detallado es necesario, antes de definir las reglas de limpieza.
Una limpieza de datos tiene como objetivo mejorar la calidad de los datos existentes, hasta el nivel máximo deseado, empleando una de las siguientes formas:
- Completar los datos faltantes, cuando debieran existir
- Corregir los datos defectuosos
La mayoría de las veces, cuando se habla de corrección de datos, se está haciendo referencia a dichas formas de limpieza. La limpieza de un dato altera el valor específico de campos individuales, reemplazando un valor que viola la regla de integridad, por otro que no la viola.
La forma de reemplazo es la que define la regla de limpieza, según la regla de validación que se esté violando y según las características del dato en cuestión. La determinación del valor de reemplazo se puede hacer utilizando una cualquiera de las siguientes técnicas:
- Insertando un valor por defecto que indique la ausencia de un dato confiable. Valor “desconocido”, “nulo”, “9999”, etc.
- Examinando patrones de error (Vg., errores comunes de tipeo) y traduciéndolos a valores válidos.
- Derivando el valor más probable por defecto, basado en el contenido de otros datos. Se conoce como “estimación” o “imputación” en el lenguaje estadístico.
- Buscando fuentes alternas o substitutas de datos para encontrar el valor de reemplazo.
La limpieza de datos es una técnica útil, pero debe practicarse con precaución; la mayoría de las veces es imperativo que el registro al que pertenece el campo sea investigado y resuelto, porque así como una corrección cuidadosa puede resolver el problema, una inadecuada lo puede multiplicar. Los principales factores que hay que tener en cuenta al hacer una limpieza, son:
- Necesidad de conciliación y verificación de cantidades cuando se requiere verificar saldos del proceso con los resultados operacionales, la estimación es problemática.
- Los líderes del área funcional y los usuarios deben conocer, con respecto a los datos operacionales, cuáles valores cambiaron y bajo qué reglas, lo que debe quedar registrado en los archivos de auditoría y control.
- El grado de precisión necesario en ciertos datos, cuando hay datos más sensibles a la precisión que otros. Por ej., una proyección de ventas no requiere tanta precisión como una corrección de tarifa.
Como norma general, la definición de las reglas de limpieza debe ser un compromiso de los líderes de las áreas funcionales. Son ellos, los propietarios de los datos, quienes trabajando con el personal de informática implementan las reglas, las documentan y las mantienen.
La corrección de los datos conocidos como de “nombres y direcciones” -también se aplica a otros tipos de dominios descriptivos- fue tratada en los procesos de estandarización, integración y transformación. Los demás datos, o sea los de maestros y los de transacciones, podrán ser corregidos utilizando los métodos descritos en este numeral.
Ahora bien, teniendo en cuenta que un dato válido no es necesariamente un dato exacto, habrá que utilizar técnicas de verificación adicionales a las mencionadas anteriormente, para descubrir datos sospechosos. Por ej., datos con valores fuera de la distribución normal; datos con valores muy altos o muy bajos, son datos sospechosos.
En lo posible, y teniendo en cuenta que estamos tratando con grandes volúmenes de datos, debemos usar procesos de corrección electrónica, dejando los procesos de revisión y corrección humana para cuando se requieran. Los datos más importantes, es decir aquellos en los cuales un error puede causar problemas catastróficos o muy costosos, deben tener comparación física con la realidad, esto es, con sus fuentes primarias.
En resumen, según el medio, los métodos para la corrección y limpieza de los datos pueden ser:
- Corrección electrónica.- Por este método se aplican las reglas de limpieza para completar y corregir los datos, así como para detectar aquellos que son sospechosos de estar errados aun cuando sean válidos. También puede utilizar fuentes redundantes, alternas o substitutas, internas o externas, en medios magnéticos.
- Corrección humana por comparación física con el objeto investigado.- Se investiga el objeto en cuestión para confirmar sus propiedades reales; se le hacen llamadas telefónicas, encuestas, etc. Es decir, se comparan los datos con su fuente primaria.
- Corrección humana por comparación con una fuente alterna o substituta.- Cuando ciertos datos no pueden ser físicamente verificados, Vg., ciertas transacciones o eventos que ya ocurrieron, tendremos que recurrir a fuentes alternas o documentos de soporte de la operación.
- Corrección híbrida.- Usando la combinación de métodos electrónicos para corregir errores obvios y métodos humanos para la verificación de los sospechosos y corrección de los que no pudieron ser corregidos electrónicamente.
Algunos datos, desafortunadamente, nunca podrán ser corregidos y, aquellos que pueden ser corregidos, usarán casi siempre una combinación de métodos electrónicos y humanos.
Para definir el tratamiento que se debe dar a los datos incorregibles, debemos involucrar a los líderes de las áreas funcionales y a los usuarios de la información. Algunas alternativas de tratamiento de estos datos, son:
- Rechazar los datos defectuosos y excluirlos para que no puedan ser propagados a su destino. Esto es viable si no afecta los resultados finales; debe hacerse con precaución.
- Aceptar los datos defectuosos sin cambios ni modificaciones, cuando su proporción es considerada baja.
- Aceptar los datos defectuosos sin cambios pero reportando que son sospechosos. Así, los usuarios podrán saber que hay problemas en ellos y en qué proporción.
- Aceptar los datos pero estimando su valor correcto o aproximado. Algunos datos podrán estimarse, Vg., fecha de nacimiento, etc. Se deben documentar los registros y campos estimados, indicando el método de estimación y su probabilidad de error. En lo posible, marcar el campo con un código que indique, entre otras posibilidades:
X: Error original, valor incorregible
E: Error original, valor estimado
F: Corregido y verificado físicamente con fue primaria
S: Corregido y verificado con fuente substituta
1.3. Revisión/Recolección Físico-Manual
Entradas:
- Archivos de datos para revisión físico manual
Fuentes de datos alternas y/o substitutas
Salidas:
- Archivos de datos revisados y completos
- Documento de revisión
1.3.1. Descripción del proceso
En este proceso se aplica la revisión manual y la recolección física sobre el terreno, de aquellos datos que no pudieron ser corregidos o completados electrónicamente y que deben ser migrados al repositorio. Los datos a recolectar deben ser previamente agrupados por unidades de observación, o sujetos del negocio, para que la recolección sea económica y eficiente, conformando así las fuentes de datos alternas y/o substitutas. De todas maneras, los archivos de datos revisados y/o completos deben pasar nuevamente por validación y limpieza, hasta lograr el nivel de calidad deseado.
Reporte de auditoría y control de la revisión física o manual: debe contener, al menos, la siguiente información:
- Conteo de registros corregidos, imputados e intactos.
- Conteo de campos corregidos, imputados e intactos.
- Conteo de registros y campos incorregibles
- Para los registros corregidos, imputados e intactos,
- Totales de control, cualitativos y cuantitativos para los campos seleccionados.
- Conciliación de los totales de control
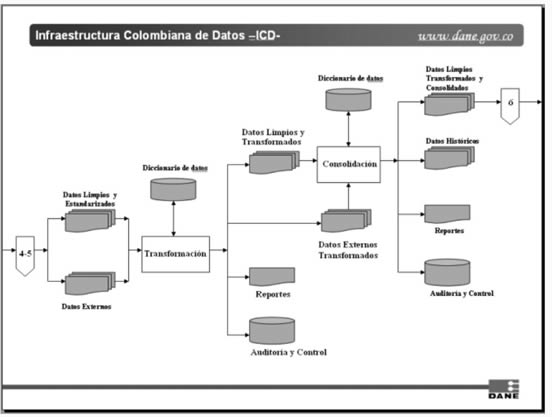
2. Procesos de Transformación y Consolidación
Durante estos procesos se transforman los datos para cargarlos en las tablas del repositorio. Esto incluye convertir y formatear datos limpios y estandarizados y mejorarlos con datos redundantes o externos, adquiridos en otras entidades generadoras de información básica. El proceso tiene dos partes: a) transformar los tipos de datos, valores de dominio, formatos, derivaciones, etc. y, b) combinar o consolidar los datos comunes, redundantes y externos, con los internos para mejorar y aumentar su valor.
Hay muchos tipos de datos que pueden ser adquiridos a entidades generadoras de información básica, como:
- Datos personales: fecha de nacimiento, sexo, estado civil, etc.
- Datos geográficos: coordenadas, latitud, longitud, etc.
- Datos postales: direcciones, estándares de direcciones, etc.
- Datos estadísticos: censos, muestras, registros administrativos y observaciones directas de población, ingresos, ocupación, etc.
- Datos económicos: tasas de cambio, inflación, etc.
- Datos socio-políticos: reglamentaciones, cambios políticos, que directa o indirectamente tienen impacto de coyuntura.
- Datos de comportamiento socio-económico: patrones de compra, de religion, estado civil, etc.
2.1. Transformación
Entradas: (Ver Gráfico 3)
- Archivos de datos limpios y estandarizados
- Datos externos de fuentes alternas
- Diccionario de datos
Salidas:
- Archivos de datos limpios y transformados
- Archivos de datos externos transformados
- Reportes de Log's del proceso
- Registros de Auditoría y Control
- Diccionario de datos
Gráfico 3. Procesos de Transformación y Consolidación
2.1.1. Descripción del proceso
El proceso aplica todas las reglas de transformación que fueron previamente identificadas y que son necesarias para que los datos a cargar cumplan con los requerimientos del repositorio de información básica. Se aplica por igual a los datos internos y externos que lo requieran.
Reporte de auditoría y control de la transformación: debe contener, al menos, la siguiente información:
- Conteo de registros con valores transformados, por campo
- Conteo de registros con valores no transformados, por campo
- Para los registros transformados y los no transformados,
- Totales de control, cualitativos y cuantitativos para los campos seleccionados.
- Conciliación de los totales de control
2.1.2. Reglas de Transformación
Las reglas de transformación que se deben definir, descubrir y documentar durante el análisis de los datos, se pueden clasificar en las siguientes categorías:
Copia simple de datos.- Los campos son copiados de un registro a otro, sin modificación, es decir, no hay transformación.
El registro es transformado (copiado) así:
Conversión de dominio.- El dominio en el campo fuente es convertido al dominio en el campo de destino. La conversión de dominio se realiza para unificar el valor del campo, su código, la unidad de medida, su formato, el tipo de dato, su longitud, etc., entre aplicaciones.
Ejemplo 1:
Ejemplo 2:
Codificación o Clasificación de datos textuales.- Los datos textuales o en formato libre son analizados y se crea una clasificación de códigos para identificar categorías.
Al transformar, queda así:
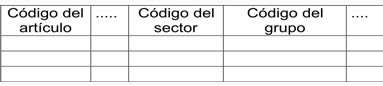
Filtro Vertical.- Cuando se descubre que un campo es usado con propósitos diferentes, se deben identificar cada uno de los usos y definirlos en el conjunto de valores respectivos del dominio. El atributo se abre en varios campos y se definen sus reglas de transformación.
En el ejemplo que se presenta, se encontró que el campo “Clase del artículo” se estaba usando en algunos casos para identificar su clasificación en el sector económico, tal como agropecuario, textil, bebidas y, en otros casos, para especificar su grupo (alimentos, vivienda, vestuario).
Al transformar, quedaría así:
Concatenación.- Dos o más valores de los datos atómicos son unidos en uno solo para dar significado a los campos. Los campos de nombres y direcciones son ejemplos de este tipo de transformaciones.
Al transformar, quedaría así:
Datos Derivados.- Son aquellos que se calculan a partir de otros y la regla de transformación expresa la fórmula o el algoritmo para su derivación. Es importante anotar que los datos, a partir de los cuales se obtiene la derivación, deben ser exactos y correctos; de otra manera, el resultado que se obtiene es errado. Es obvio que este caso no necesita ejemplos.
Datos Agregados.- Son los que aumentan la granularidad de los datos por algún concepto o característica de los mismos. La regla de transformación expresa el o los conceptos de agregación. Por ej.: Datos diarios “agregados” mensualmente, o datos agregados por categoría de productos y por área geográfica.
Los datos agregados no se deben confundir con los datos consolidados, los cuales se obtienen ensamblando datos de varias fuentes y que trataremos durante el proceso de consolidación.
2.2. Consolidación
Entradas:
- Archivos de datos limpios y transformados
- Archivos de datos externos transformados
- Diccionario de datos
Salidas:
- Archivos de datos limpios, transformados y consolidados
- Archivos de datos históricos
- Reportes de Log's del proceso
- Registros de Auditoría y Control
- Diccionario de datos
2.2.1. Descripción del proceso
Durante el proceso se conforman los registros con los datos limpios, estandarizados y transformados, tal como los requiere el repositorio de información básica.
La consolidación de los datos representa la agregación de todos los procesos de transformación. Cuando existen datos comunes en varios archivos, el proceso debe seleccionar la fuente más autorizada, de acuerdo con los criterios establecidos previamente en la evaluación de los datos. Por lo tanto, las reglas de selección constituyen la única lógica del proceso.
Los archivos de datos históricos son almacenados para su posterior utilización.
Reporte de auditoría y control de la consolidación: debe contener, al menos, la siguiente información:
- Conteo de registros de entrada y de salida
- Conteo de registros consolidados y no consolidados
- Para los registros consolidados y los no consoldados,
- Totales de control, cualitativos y cuantitativos para los campos seleccionados.
-Conciliación de los totales de control
2.2.2. Reglas de Consolidación
La consolidación de datos representa la agrupación de todos los procesos de transformación. Una agrupación es una estructura compuesta de elementos, de datos y grupos de datos, que son ensamblados para constituir un todo. El ensamble de las partes desarrolla una estructura que no cambia la granularidad. Como se vio anteriormente, un cambio de granularidad se implementa con datos agregados, que no deben confundirse con datos consolidados.
Selección de datos de varias fuentes.- Cuando existen datos comunes en varias aplicaciones, la evaluación debe determinar la fuente más autorizada. Así, al construir el registro de destino, se tomarán los atributos más confiables de cada aplicación. Este caso es parecido a la copia simple de datos, sólo que ahora intervienen dos o más archivos fuentes.
Por ejemplo, si la fecha de nacimiento de la persona se encuentra en el archivo del censo y en el registro civil de nacimientos, al construir el registro unificado de personas se tomará la fecha de nacimiento de la fuente más confiable, después de haber hecho el análisis correspondiente. En este caso, el análisis debe determinar para cada uno de los atributos, su fuente más confiable. La regla de transformación expresará el origen de cada uno de los datos.
3. Procesos de Carga
Entradas:
- Archivos planos de datos transformados y consolidados
Salidas:
- Tablas del repositorio de información básica, cargadas
- Reportes de Log's del proceso
- Registros de Auditoría y Control
3.1. Descripción del proceso
El proceso de carga es, básicamente, la aplicación de uno de los métodos utilitarios, diseñados por el proveedor de la base de datos relacional, para cargar directamente lotes de datos contenidos en los planos preparados, a las tablas del repositorio de información básica. Finalmente, un proceso de post-carga realiza la verificación de las pruebas y certifica el cargue.
Reporte de auditoría y control del cargue: debe contener, al menos, la siguiente información:
- Conteo de registros de entrada y de salida
- Conteo de registros cargados y no cargados
- Para los registros cargados y los no cargados,
- Totales de control, cualitativos y cuantitativos para los campos seleccionados.
- Conciliación de los totales de control
- Fecha y hora del cargue
- Fecha y hora de la extracción
4. Procesos de Control de Calidad
Teniendo en cuenta que el Diccionario de Datos, los Reportes de Log's del proceso y los Registros de auditoria y control son comunes a los procesos de control de calidad que deben llevarse a cabo en cada uno de los subprocesos anteriores, pasamos finalmente a describir su contenido y su utilización.
El Diccionario de Datos mantiene como metadatos, al menos, la siguiente información que se produce durante la creación y modificación de los archivos, así como durante la ejecución de cada uno de los programas y subprocesos:
- Estructura y descripción de los datos de entrada
- Estructura y descripción de los datos de salida
- Reglas aplicadas a los datos de entrada, en términos descriptivos y técnicos
- Datos de volumen y calificación de la calidad de las estructuras almacenadas
- Nombres de los programas de acceso a datos y sus características
- La identidad de los propietarios o responsables de los datos
- Referencias cruzadas de las relaciones entre entradas y salidas
- Log de creación y actualización de cada uno de sus objetos
Los Reportes de Log's del proceso presentan fundamentalmente la siguiente información:
- Nombre y versión del programa ejecutado; nombre del modelo y del grupo de la aplicación
- Valores de los parámetros externos de ejecución
- Fecha y hora de la corrida del programa
- Código de terminación del programa
- Archivos de entrada y de salida por programa
- Número de registros leídos para cada archivo de entrada
- Número de registros excluidos por el sistema, por Ej.: campos numéricos inválidos, fechas inválidas, valores del campo fuera de rango, etc.
- Número de registros excluidos del proceso por el usuario
- Número de registros escritos para cada archivo de salida
- Otros conteos de registros de entrada y de salida por programa
Esta información es generada automáticamente durante la ejecución de los programas en unos archivos (*.log) que, posteriormente, son consolidados y registrados en el diccionario de datos.
Los Registros de Auditoría y Control, (Ver Gráfico 4) contienen principalmente la información necesaria para la conciliación de los campos seleccionados, con cifras de totales de conteo y control en cada archivo de entrada y en cada salida. El objetivo de estos registros es monitorear y verificar que:
- Todos los datos que deban ser extractados, sean efectivamente extractados
- Las transformaciones se llevan a cabo de acuerdo a las especificaciones
- Los datos son cargados completamente de acuerdo a las especificaciones
- Los errores y excepciones son identificados y manejados de acuerdo a lo planeado
Gráfico 4. Procesos de Conciliación
Gráfico 4.- Procesos de Conciliación
Es de anotar que el propósito de estos registros es poder explicar las diferencias que se encuentran durante los procesos ETL, ya que los totales a la entrada no necesariamente deben ser iguales a los de la salida. Los pasos para implementar los reportes de auditoría y control se pueden resumir de la siguiente manera:
- Definir los requerimientos de control
- Teniendo en cuenta que cada uno de los procesos ETL puede implicar a múltiples programas, los puntos de control identifican las entradas y salidas de los programas sobre los cuales se reportarán los totales.
- Los campos cualitativos y cuantitativos sobre los cuales se deben discriminar y agrupar los totales de control y conciliación.
- Desarrollar los programas que se deben producir en cada punto de control, discriminados por los conceptos definidos en el paso anterior.
Los programas de control deben generar, además de los reportes de los conteos o valores del o de los campos de control discriminados por dominio, un archivo de control (*.ctl). Estos archivos de control son posteriormente consolidados y registrados en el diccionario de datos.
Bibliografía
Brackett, Michael H., Data Resource Quality: Turning Bad Habits into Good Practices. Englewood Cliffs, NJ: Addison Wesley Longman, 2000.
Duncan, Karolyn and Wells, David, Rule Based Data Cleansing. The Journal of Data Warehousing, Fall, 1999.
English, Larry P., Improving Data Warehouse and Business Information Quality. New York: John Wiley and Sons, 1999.
English, Larry P., Information Quality Assessment, Data Cleansing and Transformation Processes. The Data Warehousing Institute: The fifth annual Implementation Conference, 2000.
Loshin, David, Enterprise Knowledge Management: The Data Quality Approach. San Francisco, Morgan Kaufmann, 2001.
Olson, Jack E., Data Quality: The accuracy Dimension. San Francisco, Morgan Kaufmann, 2003.
Villan Criado, Ildefonso y Bravo Cabria, María Soledad, Procedimientos de Depuración de Datos Estadísticos, EUSTAT, Cuaderno 20, Seminario Internacional de Estadística en Euskadi, 1990.
Wells, David, Techniques for Extracting, Transforming and Loading Data. The Data Warehousing Institute: The World Conference Spring, 2001.
1 Ver ib Revista de Información Básica, No. 2, artículo del mismo autor.
2 Ver ib Revista de Información Básica, No. 2, artículo del mismo autor. |