Resumen
La certificación es un medio para asegurar que todos los datos producidos por un proceso tengan los niveles de calidad requeridos. La certificación implica definir y cuantificar las medidas de calidad. Las certificaciones efectuadas o aplicadas a los datos deben registrarse de tal manera que la base de datos quede asociada a su certificación. Los usuarios de los datos, sean personas o sistemas, deben saber si una base de datos ha sido o no certificada.
En este artículo se presenta un cierto número de técnicas de medición de calidad de los datos, que son relativamente fáciles de implementar y que tienen un alto impacto positivo en la disposición de una organización para mejorar sus datos.
En cinco pasos simples, este enfoque práctico, combinado con seis niveles de sofisticación de calidad de los datos, permitirá construir una base sólida para los esfuerzos de mejoramiento de las entidades productoras de la información básica: consistencia de la definición, ocurrencias duplicadas, cubrimiento de valores, cumplimiento de las reglas de validación, exactitud con las fuentes primarias y sustitutas, y equivalencia de datos redundantes.
Igualmente, se presenta una clasificación y descripción casi exhaustiva de las reglas de validación que deben aplicarse durante el análisis y evaluación de la calidad, a partir de la elaboración de un modelo que facilite el conocimiento de las propiedades y relaciones entre los datos.
Palabras Claves
Calidad de datos, Reglas de calidad de datos, Reglas de validación, Reglas del negocio, Certificación de calidad de datos estadísticos.
Abstract
Certification is a means of ensuring that all of the data produced by a data management process meets the quality levels required. Certification involves defining and reporting quality metrics. The certifications performed or applied to the data should be recorded so that the data set is associated with the certification. Users, whether they are systems or people, should be able to see whether or not a data set has been certified.
This paper will present a number of data quality measurement techniques that are relatively easy to implement, and will have a significant positive impact on an organization's ability to leverage its data.
In five simple steps, this practical approach, combined with the six levels of data quality sophistication will allow you to build a solid base for the data quality efforts of the producer entities of basic information: consistency of definition, uniqueness, completeness, validation rules conformance, accuracy with the primary and secondary source, and overlaps of data as replicas and derivations are created and stored.
This paper also presents an almost exhaustive classification and description of the validation rules that should be applied during the data quality analysis and assessment, based on a data model to acquire the knowledge of their properties and discover the relations among data.
Keywords
Data Quality, Data Quality Rules, Validation Rules, Business Rules, Statistical Data Quality Certification.
Introducción
Para estas actividades suponemos que, mediante las primeras reuniones o visitas de inspección a la entidad productora de información básica EPIB-, ya se ha identificado el inventario de las fuentes de datos; las bases de datos; las tablas de referencia y los archivos departamentales internos utilizados en la producción de las operaciones estadísticas que deben ser analizadas y evaluadas. Para todos ellos debe existir la documentación de la estructura y definición de los datos.
Por su contenido, los archivos fuentes de una operación estadística son de dos categorías: los archivos de eventos, características o propiedades de la unidad de observación y los archivos o tablas de referencia. En los primeros, sus valores están determinados por una ocurrencia de las características de la unidad de observación investigada; en los segundos, sus valores le dan contexto a las propiedades de la unidad observada.
De acuerdo al método o sistema de recolección, los datos de una operación estadística pueden provenir de diversas fuentes, entre las cuales consideramos las siguientes posibilidades:
-Censos
-Muestras
-Registros administrativos
-Observaciones sobre el terreno
Una estrategia de análisis y evaluación de la calidad de los datos estadísticos puede tener uno o más de los siguientes objetivos:
- Entender y documentar la calidad y confiabilidad de los datos.
- Descubrir en los datos los problemas de calidad que deben ser resueltos durante los procesos de preparación y carga hacia el repositorio de información básica.
- Asegurar la armonización, estandarización e integración de los datos comunes en las diferentes operaciones estadísticas.
- Especificar las reglas de transformación y validación que deben aplicarse a los datos, para asegurar el nivel de calidad que se requiere en una migración hacia el repositorio de información básica.
Los pasos a seguir durante el análisis y la evaluación de calidad de los datos, son:
- Seleccionar los grupos de información y los archivos a evaluar.
- Identificar las fuentes de verificación de los datos.
- Diligenciar la ficha técnica de la evaluación cuantitativa.
- Seleccionar y documentar los tipos de reglas de validación a evaluar.
- Cuantificar y documentar los tipos de defectos en los datos.
A continuación se describe cada uno de los pasos que se deben llevar a cabo durante el análisis y evaluación de la calidad de los datos. Cada paso se debe documentar en los formatos diseñados para tal fin. Estos formatos están disponibles y pueden solicitarse en CANDANE o en el Laboratorio de Cibernética de la Unidad Científica del DANE.
1. Seleccionar los grupos de información
Dado que los archivos fuentes de una operación estadística pueden ser numerosos, el objetivo de este paso consiste en identificar aquellos conjuntos de datos en donde una mala calidad cause un impacto desfavorable y significativo en los productos estadísticos. El grupo de información puede incluir varios atributos de uno o más archivos, tomando siempre el origen de los datos, incluyendo los comunes, para determinar la efectividad del proceso de recolección o captura. Un grupo de datos puede corresponder a un producto, medida o indicador estadístico crítico o a una agrupación lógica de datos centrados alrededor de una clase temática de la unidad de observación.
Cada grupo debe ser calificado cualitativamente por la importancia relativa que causan los datos incorrectos en los indicadores o productos que generan, con “A =Impacto Alto”, “M =Impacto Medio”, o “B =Impacto Bajo”. Debe anotarse que un impacto alto requiere de una corrección real de los datos defectuosos; un impacto medio aceptaría una imputación del valor por un método estadístico de estimación; mientras que un impacto bajo se podría resolver con una asignación del valor por defecto.
Se deben seleccionar, por lo menos, aquellos grupos de información que tienen un impacto alto o medio en el (los) producto(s) que generan. Un grupo de datos manejable para evaluación puede consistir de uno a diez archivos, con sus correspondientes campos identificados (de 3 a 30), dependiendo de la operación estadística por evaluar.
2. Identificar las fuentes de verificación de los datos
Además de los datos externos, se deben identificar las fuentes autorizadas de información, las cuales son utilizadas para verificar y corregir, por métodos humanos o electrónicos, los datos errados o sospechosos. Estas fuentes autorizadas son de dos clases:
- Primarias.- Están constituidas por el objeto mismo de investigación, o por observación física de los eventos.
- Sustitutas.- Las conforman documentos de soporte originales, o registros administrativos, que reflejan auténticamente la fuente.
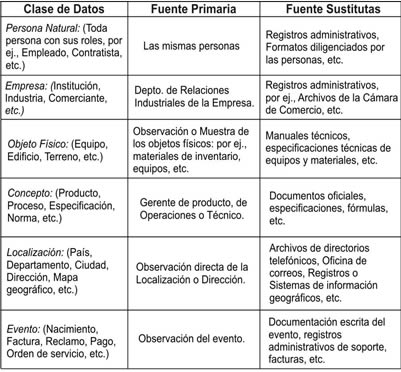
Para cada categoría de Entidad se deben determinar las fuentes primarias y las sustitutas, dado que dentro de una categoría las fuentes de verificación son similares. Estas categorías son seis: Persona, Empresa, Objeto físico, Concepto, Localización y Evento.
Ejemplos de fuentes de verificación por clase de datos:
Para propósitos de exactitud, es importante diferenciar la confirmación de valores entre las fuentes sustitutas y las primarias, teniendo en cuenta que aquellas podrían ser menos exactas, aunque también menos costosas.
En cuanto a los registros administrativos, o archivos secundarios que se identifiquen y seleccionen para completar o verificar los datos, antes de utilizarlos es necesario conocer:
- La definición y significado de los datos.
- La fuente y metodología de recolección.
- La fecha de recogida y su frecuencia de actualización. - El nivel de calidad de la información; su grado de cobertura, confiabilidad y margen de error.
- Si se usaron técnicas de estimación para completar los datos, qué porcentaje ha sido estimado y con qué método.
3. Diligenciar la ficha técnica de la evaluación cuantitativa
En este paso se deben identificar los tipos y las características de evaluación de calidad de los datos. La ficha técnica debe indicar la clase y forma como se realizaron las pruebas y las clases de pruebas que se realizaron. Es similar al reporte de auditoria de los estados financieros.
El tipo de evaluación define si ella se va a efectuar en forma manual o electrónica; sobre la población total o sobre una muestra seleccionada estadísticamente, en cuyo caso se deben documentar los parámetros de selección del tamaño, el nivel de confianza y el porcentaje de error.
En una evaluación electrónica los datos en medios magnéticos se procesan en un computador para analizar el cumplimiento de las reglas de validación. Sin embargo, cuando el volumen de los datos es pequeño, dichas reglas de validación se pueden comprobar manualmente. En una evaluación física se verifica la calidad de los datos de manera que sean correctos y estén acordes con la realidad que representan, utilizando las fuentes primarias y sustitutas.
Las características de evaluación son los aspectos de calidad que interesan y son los más relevantes en la elaboración de las estadísticas. Para identificarlas en este paso se debe tener en cuenta los métodos cuantitativos de obtención de sus medidas. A continuación, se presentan las características de calidad más importantes que deben considerarse, y el método de obtención de sus medidas:
- Consistencia de la definición.- Es la concordancia del contenido del dato1 con su definición. Su medida se obtiene por la existencia o no de la concordancia.
- Cubrimiento de valores.- Es la característica de tener todos los datos con los valores requeridos. Su medida es el porcentaje de registros que tienen un valor NOTNULL (valores no faltantes) para un dato específico. El complemento es el porcentaje de valores faltantes. Para el cálculo del porcentaje de faltantes no se debe tener en cuenta aquellos valores que no aplican al sujeto investigado.
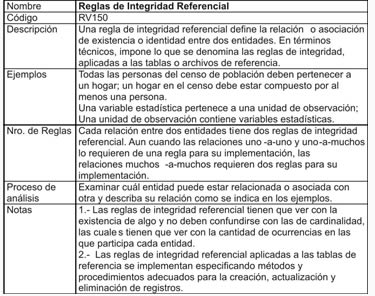
- Cumplimiento de las reglas de validación.- Ver documento anexo: “Reglas de Validación”: Los datos deben cumplir los diferentes tipos de reglas, precisadas en dicho anexo. Su medida es el grado de cumplimiento de las éstas y se expresa como el porcentaje de registros y de campos con valores que cumplen con las mismas para un dato específico. A manera de ejemplo, las clases de pruebas de validación incluyen: valores de dominios, rangos, llaves primarias únicas sin duplicados, integridad referencial, reglas de dependencia, consistencia de formatos, etc. Es importante anotar que un valor de campo, por ser válido, no necesariamente significa que sea exacto o correcto.
- Exactitud con la fuente sustituta.- Significa que el dato es el mismo que contiene una fuente sustituta autorizada, generalmente el documento de origen o una forma electrónica externa no alterada. Su medida es una evaluación del porcentaje de registros y de campos cuyos valores para un dato específico son exactos, comparados con los valores de la fuente original autorizada. Se debe anotar que esta forma de evaluación no es perfecta, ya que las personas que llenan los documentos de soporte cometen errores, lo mismo que las formas electrónicas pueden introducir errores de varios tipos.
- Exactitud con la fuente primaria.- El dato refleja exactamente la realidad del objeto o evento que describe. Es el más alto grado de exactitud de información posible, ya que se está evaluando el dato contra su valor, observado físicamente. Para la evaluación con la realidad se requiere confirmar el valor del dato con la medida del objeto o la observación del evento. Su medida es el porcentaje de registros y de campos cuyos valores para un dato determinado han sido confirmados como correctos con sus valores actuales. La escogencia entre la evaluación con una fuente sustituta o con la realidad, depende del impacto negativo que causan los datos incorrectos en el producto estadístico que afectan. Los costos involucrados son más altos en la evaluación con la realidad, pero se pueden disminuir con la toma de muestras estadísticas. Un ejemplo de evaluación con la realidad es la observación en el terreno de las características de una unidad censal.
- Ocurrencias Duplicadas.- Es un caso especial de validación de integridad y representa el grado de correlación unívoca (uno a uno) entre el registro y el objeto o evento que representa. Su medida es el porcentaje de registros que son duplicados de otros registros dentro en una colección de datos. Por registros duplicados no sólo queremos decir que tengan valores idénticos de identificación, sino también que los registros sean representaciones duplicadas del mismo objeto o evento del mundo real.
- Equivalencia de datos redundantes.- Es el grado con el cual los datos de una colección o base de datos son semánticamente equivalentes a los datos del mismo objeto o evento en otra colección o base de datos. Semánticamente equivalentes significa que los valores son iguales en su concepto; es decir, significan lo mismo en ambos lugares, aun cuando tengan distinto valor. Por ej., si el sexo de J. López es M por masculino en uno y en el otro lugar es 1 por masculino para el mismo J. López, hay equivalencia. La medida de equivalencia es el porcentaje de campos en los registros de una colección que son semánticamente equivalentes a sus respectivos campos en la otra colección de datos.
Sobre los datos comunes o redundantes en archivos se debe determinar la fuente de datos más confiable, ya que posteriormente se deberán consolidar.
Las principales guías para seleccionar las fuentes más confiables, son:
- Los datos tienden a ser más confiables, entre más crítico sea el proceso para la entidad productora de la información básica EPIB-, que, como fuente, los crea y actualiza. Por ej., el salario de una persona tomado del departamento de personal de la empresa donde trabaja, es más confiable que el registrado en una solicitud de apertura de cuenta bancaria.
- L os datos actualizados frecuentemente son, en general, más exactos que los datos viejos.
-Los datos creados y actualizados por personas responsables del proceso son más confiables que los actualizados por terceros, cuando no tienen incentivos para capturarlos correctamente. Si la labor de un funcionario es medida por la calidad de la información que produce, ésta tenderá a ser más confiable.
-Los datos históricos, como “fecha de iniciación del servicio” deben ser extractados de la ocurrencia más antigua del registro.
4. Seleccionar y documentar los tipos de reglas de validación a evaluar
En este paso se especifican y describen, en detalle, los diferentes tipos de reglas de validación que debe aplicarse a los datos para evaluar su nivel de calidad.
El analista de datos debe ayudarse de un modelo lógico para descubrir y especificar cada una de las reglas, de acuerdo con las guías documentadas en el anexo “Reglas de Validación”.
5. Cuantificar y documentar los tipos de defectos en los datos
En este paso se analizan los datos para descubrir y cuantificar sus defectos. Las medidas son el resultado cuantificado de la evaluación de las características y reglas seleccionadas anteriormente.
Durante la evaluación se extraen los datos fuentes, se observan y se analizan para confirmar sus definiciones y sus contenidos, o para descubrir los defectos o anomalías que deben cuantificarse durante el proceso de evaluación.
El descubrimiento de los datos sospechosos puede hacerse sobre el 100% de los registros para archivos pequeños, o utilizando muestreo estadístico para consultas manuales o automatizadas sobre los datos, como las de aceptación de atributos, descubrimiento de atributos, materialidad, etc., de manera que podamos hacer la inferencia de los resultados sobre el total de la población.
Al finalizar el análisis de calidad de los archivos, o bases de datos fuentes, se deben interpretar y presentar los resultados: clasificar los problemas o patrones de calidad en los datos, listar y analizar dos o tres ejemplos representativos de cada tipo y cuantificar los tipos de defectos en los datos, estimando su frecuencia.
Es importante anotar que los errores más frecuentes, no necesariamente significan los errores que mayores impactos negativos producen; por lo tanto, el impacto o el costo del error debe tenerse en cuenta al presentar los reportes.
En general, según se describió en las características de evaluación, se puede decir que los tipos de errores están clasificados en las siguientes categorías:
- Inconsistentes por definición.
- Faltantes, es decir, no existe el dato o es nulo o blanco, cuando debiera existir.
- Inválidos, cuando no cumplen alguna regla de validación; en este caso, se debe especificar la regla violada.
- Incorrectos, cuando no concuerdan con la realidad.
- Duplicados, es decir, existen varias identificaciones del mismo sujeto.
- Discrepancia con datos redundantes.
Los reportes deben presentarse gráficamente, o en hojas de cálculo, incluyendo, en lo posible, diagramas de Pareto, en las siguientes formas:
Reportes de Resumen de medidas.- Incluyen generalmente representaciones gráficas del resumen de los resultados. Resumen de errores por grupo de información, por registro, por campo.
Reportes Detallados de calidad.- En este reporte se presentan unos resultados por tipos de error en el campo, y otros por tipos de error en el registro. Por ej., el campo dirección, puede tener errores en el formato de la calle, o la calle es incorrecta, o falta la ciudad, o está incompleta, etc.
Cuadro 1.- Diferencia de conteo para campos y registros
Reportes de Discrepancia.- Estos reportes comparan la equivalencia o consistencia de los datos cuando existen registros del mismo objeto o evento en múltiples bases de datos. Ellos ilustran la sincronización entre archivos redundantes y muestran sus problemas de inconsistencia.
Reportes de Excepción.- Simplemente muestran el descubrimiento de los datos encontrados errados y sus valores correctos.
En los formatos diseñados en el Laboratorio de Cibernética del DANE, se pueden apreciar algunos ejemplos de reportes de evaluación de calidad, cuantificando defectos por registros y por campos.
ANEXO I
Reglas de validación
Las reglas de validación son aquellas que prueban la integridad de los datos. Los modelos de datos, cuando existen, ayudan a localizar dichas reglas. Debemos recordar que un dato válido no necesariamente significa que sea correcto.
Durante los procesos de validación, se evalúa la integridad de los datos de cada archivo, mientras que en los procesos de limpieza se definen las acciones a tomar en caso de errores o inconsistencias en los mismos. Por ejemplo, efectuar imputaciones. Por lo tanto, se puede afirmar que las reglas de validación y limpieza se implementan en dos pasos: a) las reglas que prueban la integridad de los datos y b) la especificación de las acciones a tomar cuando se encuentra una violación de integridad.
Las reglas de validación se pueden utilizar para evaluar la calidad de los datos y/o, para filtrarlos y/o, para corregirlos. Recordemos que una estrategia de validación de los datos tiene, entre otros, uno o más de los siguientes objetivos:
- Entender y documentar la calidad y confiabilidad de los datos, es decir, su perfil.
- Descubrir en los datos los problemas de calidad que deben ser resueltos durante los procesos de validación y limpieza.
- Especificar las reglas de validación que deben aplicarse a los datos para asegurar el nivel de calidad que se requiere en una migración, una conversión o una carga de datos a un repositorio.
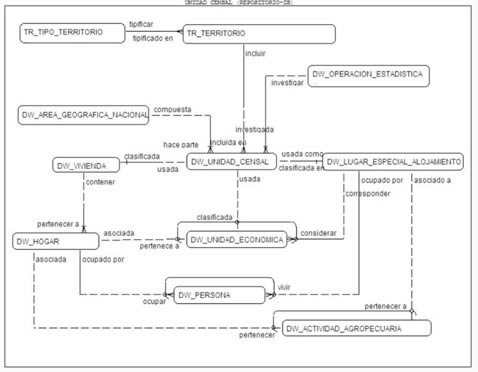
Los modelos lógicos de datos representados en un diagrama de entidad relación ERD-, permiten identificar un conjunto relativamente robusto de reglas de validación, analizando su estructura. Por lo tanto, es de suponerse que el profesional responsable de la evaluación, no sólo debe estar familiarizado con el modelamiento de datos sino que, además, ha debido construir, previamente al análisis y determinación de las reglas a validar, el modelo lógico correspondiente a los datos de su interés.
El modelo de datos que se muestra en la figura No. 1, corresponde a una porción del repositorio de los datos del Censo General 2005 en Colombia. La mayoría de los ejemplos utilizados para explicar los diferentes tipos de reglas de validación son tomados de dicho modelo.
Figura No. 1.- Diagrama Entidad Relación de la Unidad Censal
Las reglas de validación de los datos, las clasificamos de la siguiente manera2:
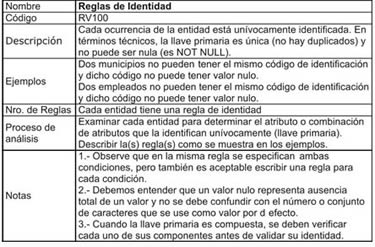
- Reglas de Identidad
- Reglas de Integridad Referencial
- Reglas de Cardinalidad
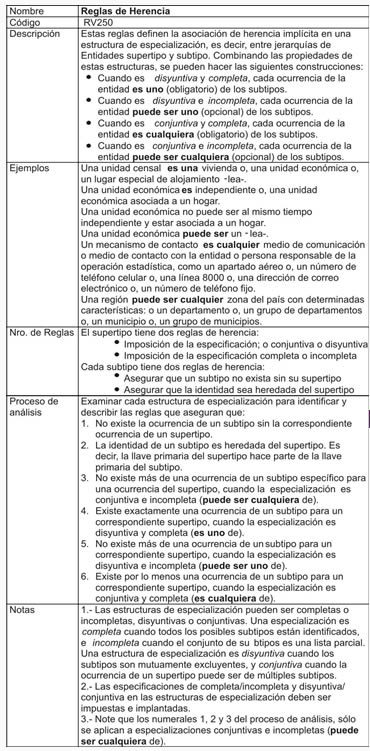
- Reglas de Herencia
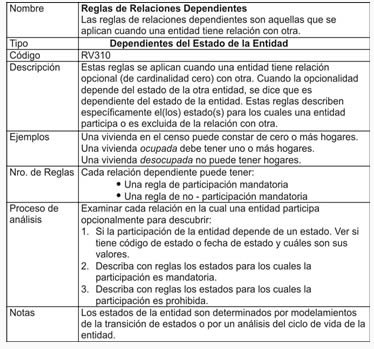
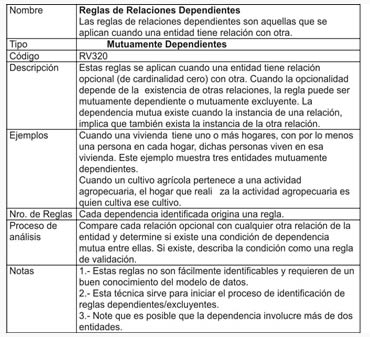
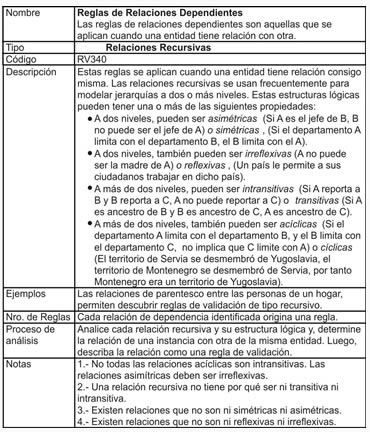
- Reglas de Relaciones Dependientes
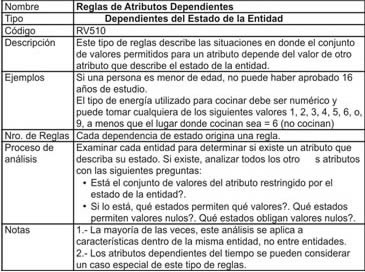
- Dependientes del estado de la Entidad
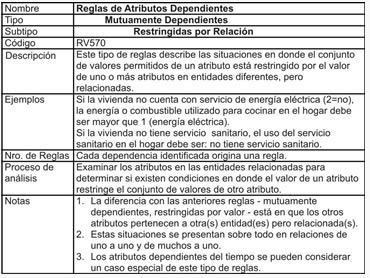
- Mutuamente Dependientes
- Mutuamente Excluyentes
- Relaciones Recursivas
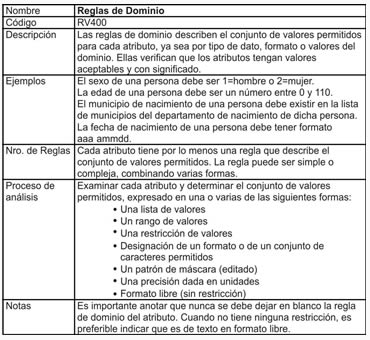
- Reglas de Dominio
- Reglas de Atributos Dependientes
- Dependientes del estado de la Entidad
- Mutuamente Excluyentes
- Mutuamente Dependientes
- Derivadas
- Restringidas
- Por valor
- Por Relación
Los primeros cuatro tipos de reglas están “explícitas” en el modelo lógico de datos de entidad relación y pueden ser extraídas directamente del modelo cuando éste ya existe. Los tipos de reglas restantes están implícitas en el modelo de datos y requieren de algún análisis o investigación para descubrirlas o identificarlas específicamente. De todas maneras, ya sea el tipo de regla explícito o implícito, el método de usar el modelo de datos para documentarlas es un paso importante y necesario para evaluar su calidad.
Las reglas de validación se pueden describir en términos comunes, o en términos técnicos -usando la terminología de las bases de datos-, v.g., llave primaria, llave foránea, valores nulos, tablas, columnas, etc. Se deben usar los términos adecuados, según la audiencia a la que se dirijan.
A continuación, pasamos a describir cada uno de los tipos de reglas que, en su conjunto, representan una clasificación relativamente exhaustiva, para que sean utilizadas como referencia, en una etapa de evaluación en la calidad de los datos.
En los ejemplos que se presentan usaremos términos comunes para describir las reglas.
Como puede observarse, un modelo de datos puede proporcionar la descripción de un gran número de reglas de validación. El número de reglas inherentes, sin contar las de dependencia, puede ser aproximadamente estimado usando la siguiente expresión:
Número de reglas = (número de entidades) +
(número de relaciones*3) +
(número de atributos) +
(número de sub-tipos*2) +
(número de super-tipos*2)
Para la identificación de estas reglas, existe una variedad de técnicas entre las cuales la más utilizada es la construcción del modelo lógico de datos. El diseño de los cuestionarios, su documentación y las tablas de referencia entre otros, también ayudarán a verificar las reglas encontradas en el modelo.
Bibliografía:
English, Larry P., Improving Data Warehouse and Business Information Quality. New York: John Wiley and Sons, 1999.
English, Larry P., Information Quality Assessment, Data Cleansing and Transformation Processes. The Data Warehousing Institute: The fifth annual Implementation Conference, 2000.
Brackett, Michael H., Data Resource Quality: Turning Bad Habits into Good Practices. Englewood Cliffs, NJ: Addison Wesley Longman, 2000.
Olson, Jack E., Data Quality: The accuracy Dimension. San Francisco, Morgan Kaufmann, 2003.
Ross, Ronald G., The Business Rule Book: Classifying, Defining & Modeling Rules, Business Rule Solutions (1997).
Duncan, Karolyn and Wells, David, Rule Based Data Cleansing. The Journal of Data Warehousing, Fall, 1999.
|